Are you working on the intersection of Machine Learning and Model Driven Engineering? We have three domain-independent encodings that can help you to achieve better results:
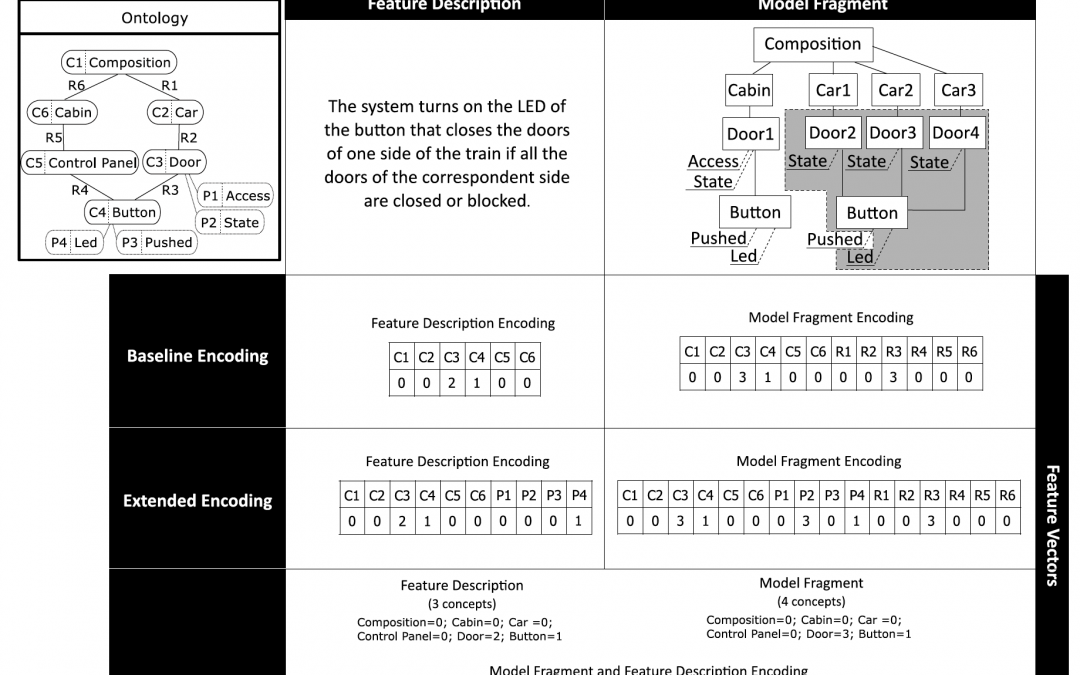
The Source Encoding: this encoding is based on the main concepts and relations of a domain ontology.
The Extended Encoding: This second encoding is based on the main concepts, properties, and relations of a domain ontology. In other words, this encoding is an extension of the source encoding taking into account the whole ontology.
The Mapped Encoding: The mapped encoding adapts the sum of term frequency and the mean of term frequency characteristics taking into account the frequency of the concepts, the properties, and the relations instead of the frequency of the terms.
Our public online repository contains the source code of the machine learning approach, the source code of the four encodings, the classiers for all the trainings, and one of the test cases. Furthermore, the implementation for the Information Retrieval approach and the Linguistic rule-based approach is also available in the same repository under the names of TLR-LSI and TLR-Linguistic, respectively.
Recent Comments