Tools and Datasets

Phylogenix: Bringing phylogenetics to Unity
Phylogenix enables developers to analyze prefabs and generate a phylogenetic tree of any video game developed in Unity. Our tool, Phylogenix, is composed of two different parts: a Unity plugin, which analyzes Prefabs, realizes the phylogenetic inference, and generates...
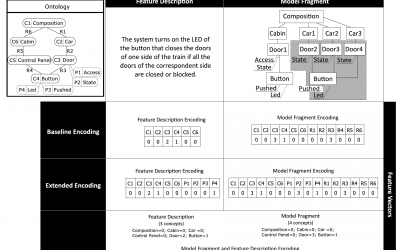
Implementation of our three domain-independent encodings for using software models (MDE) with machine learning techniques in the context of feature location.
Are you working on the intersection of Machine Learning and Model Driven Engineering? We have three domain-independent encodings that can help you to achieve better results: The Source Encoding: this encoding is based on the main concepts and relations of a domain...
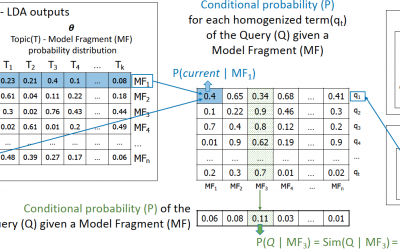
Implementation of topic modeling (LDA) for feature location
Latent Dirichlet Allocation (LDA) is one of the most popular topic modeling methods. Topic modeling is a popular and promising information retrieval technique that represents topics by word probabilities. Here you cand find our open-source implementation of the LDA...
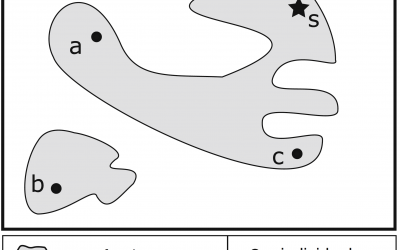
Implementation of strategies for nonconforming individuals when searching in model artifacts
The search space can be huge when searching in model artifacts (magnitudes of around 10150 for models of 500 elements). By handling the nonconforming individuals, the search space can be drastically reduced. We present a set of nine generic strategies for...
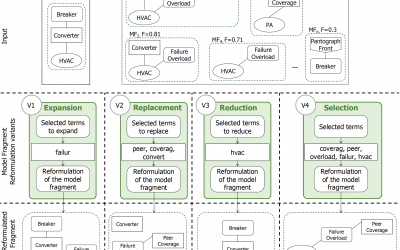
Implementation of automatic Query Reformulations as Genetic Operations
In the combination of Model-Driven Engineering (MDE) and Search-Based Software Engineering (SBSE), genetic operations are one of the key ingredients. Our work proposes a novel adaptation of automatic query reformulations as genetic operations that leverage...
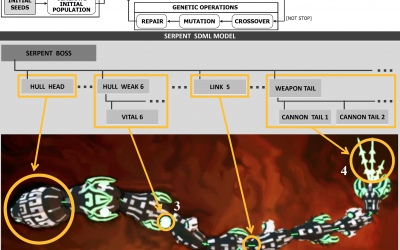
EMoGen tool: Evolutionary Model Generation
EMoGen generates software models that are comparable in quality to the models created by human developers. Automatically generating human-competitive software models is a challenging task. Fully achieving it spans the creation of model elements, the...
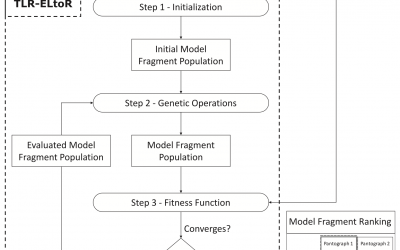
TLR-ELtoR tool: Evolutionary Learning to Rank for Traceability Link Recovery )
TLR-ELtoR recovers traceability links between a requirement and a model through the combination of evolutionary computation and machine learning techniques, generating as a result a ranking of model fragments that can realize the requirement. Our public online...
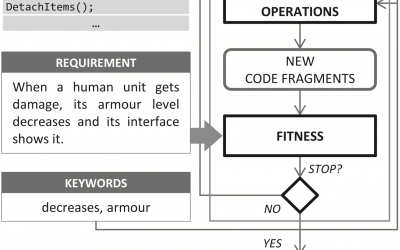
CODFREL tool: Code Fragment-based Requirement Location
Current traceability approaches evaluate methods in the source code of a software product as atomic units. CODFREL (Code Fragment-based Requirement Location) is our approach to fine-grained requirement traceability, which lies in an evolutionary algorithm and includes...
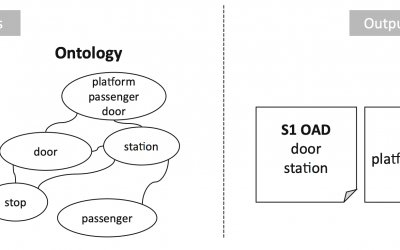
LORE tool: Natural Language Processing + Ontological Requirement Expansion
Often, when requirements are written, parts of the domain knowledge are assumed by the domain experts and not formalized in writing, but nevertheless used to build software artifacts. This issue, known as tacit knowledge, affects the performance of Traceability Links...
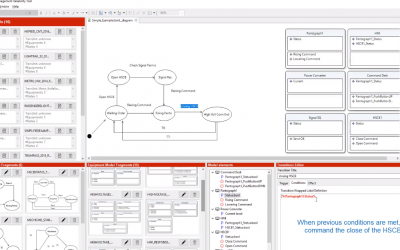
Know our Train Control & Management System (TCMS) Variability Tool
TCML has expressiveness to describe the iteration between the main pieces of equipment installed in a train unit. From a TCML model, it is possible to extract model fragments and keep them in a model fragment library. These model fragments can be reused in the...
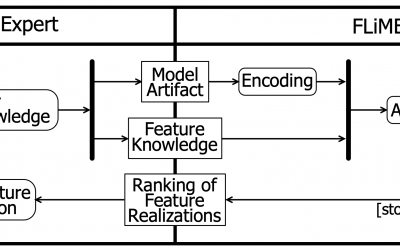
FLiMEA tool: Feature Location in Models by an Evolutionary Algorithm
Feature location is one of the most important and common activities performed by developers during software maintenance and evolution. Features must be located across families of products and the software artifacts that realize each feature must be identified....
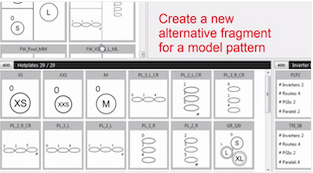
See our Model Patterns Variability Tool
The model library of the tool was populated thanks to our model pattern identification and extraction process. The process faced the following settings from our industrial partner: models composed of more than 500 elements. Around 1029 different potential fragments...
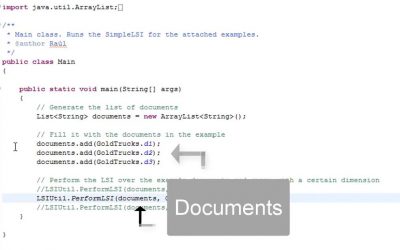
SVIT implementation of LSI
Latent Semantic Indexing is a powerful machinery to calculate similitude among texts. Our implementation is complaint with the theoretical results of the “Gold Tucks” example.
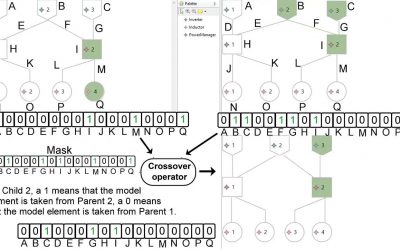
Genetic Manipulation of Model Fragments!
Our encoding and genetic operations enable the production of crossed and mutated model fragments. The resulting model fragments are still part of an original product model, and therefore, they keep the conformance to the metamodel